19.01.2024
4
Beğenme
355
Görüntülenme
Veri Madenciliği (Data Mining): Bilgi Hazinelerini Keşfetme Sanatı
Merhaba arkadaşlar! Bu yazıda size günümüzde teknolojinin en heyecan verici konularından biri olan veri madenciliğinden bahsedeceğim. Beraber bilgisayar evreninde, veri setlerinin gizemli dünyasında kaybolup veri madenciliğinin kapılarını aralayacağız. 🚀

photo by Image Creator from Microsoft Designer
Veri Madenciliği Nedir ?
Veri madenciliği adeta dijital dünyada define avına çıkmak gibidir. Büyük veri setlerini inceleyerek, içlerindeki gizli bilgileri ortaya çıkarmak ve anlamak için kullanılan bir süreçtir. Yani her gün etrafımızda biriken o kadar çok veri var ki, bu verileri kullanarak önemli bilgileri bulup çıkarmak, işte tam da veri madenciliğinin ne işe yaradığını anlamamıza yardımcı olabilir.
Veri madenciliğinin tarihçesi oldukça ilginç bir evrimi içeriyor. 1980'lerde, bilgisayarlar ve veri depolama kapasitelerindeki artış, büyük veri setlerinin ortaya çıkmasına neden olmuştur. Ancak, bu verilerin içindeki değerli bilgileri çıkarmak için bir yöntem gerekiyordu. İşte bu noktada, veri madenciliği sahneye çıkmıştır.
İlk olarak, 1990'larda istatistik, yapay zeka ve bilgisayar bilimleri alanındaki gelişmelerle birlikte kullanılmaya başlandı. Başlarda “bilgi keşfi” (knowledge discovery) olarak adlandırılan bu süreç, daha sonra “veri madenciliği” terimiyle anılmaya başlandı. İsminin veri madenciliği olarak seçilmesi, bu sürecin veri setlerindeki değerli bilgileri keşfetme ve çıkarma sürecine benzetilmesinden kaynaklanır. Bu, sanki bir madenci toprak altındaki altını arar gibi veri madencileri de büyük veri setlerinin içinde dolaşarak değerli bilgileri bulmaya çalışırlar.
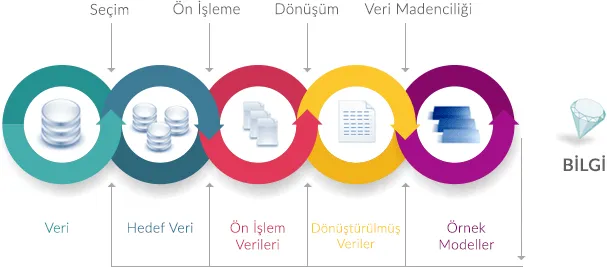
Veri Madenciliği Akış Şeması [1]
Veri Madenciliği Adımları:
Veri madenciliği, büyük veri setleri içindeki desenleri, bilgileri ve anlamlı ilişkileri keşfetme sürecini ifade eder. Bu süreç, genellikle veri analitiği, istatistik ve makine öğrenimi tekniklerini içerir. İşte veri madenciliği süreçlerinin genel adımları:
1- Problem Belirleme:
Veri madenciliği süreci genellikle bir sorunun çözümü veya bir hedefin elde edilmesi amacıyla başlar. Bu aşamada, üzerinde çalışılacak konu belirlenir ve hedefler netleştirilir.
2- Veri Toplama:
Veri madenciliğinde anlamlı sonuçlar elde edebilmek için geniş ve çeşitli veri setlerine ihtiyaç duyulmaktadır. Bu veriler farklı kaynaklardan elde edilebilir. Örneğin veri tabanları, web siteleri, sensörler veya diğer veri depolama sistemleri.
3- Veri Temizleme ve Ön İşleme:
Veri setlerinde genellikle eksik, hatalı veya tutarsız veriler bulunabilir. Bu nedenle veri temizleme ve ön işleme adımında veri setleri düzenlenir, gereksiz veriler temizlenir ve veri formatları standart hale getirilir.
4- Veri Keşfi (Exploratory Data Analysis — EDA):
Bu aşamada, veri madencisi veri setini görselleştirir ve istatistiksel analizler yaparak veri içindeki desenleri ve eğilimleri anlamaya çalışır. Bu adım, veri setinin genel özelliklerini anlamak için yapılır.
5- Özellik Seçimi (Feature Selection):
Veri setindeki özelliklerin sayısını azaltmak için özellik seçimi yapılır. Bu, modelin karmaşıklığını azaltabilir ve aynı zamanda gereksiz veya korele özelliklerin model performansını olumsuz etkilemesini önler.
6- Model Geliştirme:
Veri madenciliği sürecinin en önemli aşamalarından biridir. Bu adımda, seçilen özelliklere dayanarak bir veya birden çok makine öğrenimi modeli geliştirilir. Model türleri, veri setine ve problem türüne bağlı olarak değişebilir. (Örneğin sınıflandırma, regresyon veya kümeleme)
7- Model Eğitme:
Model önceden belirlenmiş etiket veya sonuçlarla eğitilir. Bu, modelin giriş özelliklerini ve çıktıları arasındaki ilişkileri öğrenmesine yardımcı olur. Eğitim veri seti genellikle veri madenciliği modelinin performansını değerlendirmek ve iyileştirmek için kullanılır.
8- Model Değerlendirme:
Model eğitildikten sonra bir test veri seti kullanılarak modelin performansı değerlendirilir. Burada amacımız modelin genelleme yeteneğini değerlendirmektir. Doğruluk, hassasiyet, özgüllük gibi metrikler, makine öğrenimi ve istatistiksel model performansını değerlendirmek için kullanılan ölçümlerdir. Eğer model istenilen performansı sağlamazsa geri dönüp veri temizleme veya model parametreleri üzerinde iyileştirmeler yapılabilir.
9- Sonuçların Yorumlanması ve Uygulanması:
Elde edilen sonuçlar yorumlanır ve çıkarımlar yapılır. Bu aşamada, veri madenciliği sürecinin başlangıcındaki hedeflere ne kadar yaklaşıldığı değerlendirilir. Elde edilen bilgiler, karar alıcılar için anlamlı ve kullanılabilir hale getirilir.
KAYNAKLAR:
1-) https://vizyonergenc.com/icerik/5-temel-soruda-veri-madenciligi-data-mining-nedir
2-) Wu, W. T., Li, Y. J., Feng, A. Z., et al. (2021). Data mining in clinical big data: the frequently used databases, steps, and methodological models. Military Med Res, 8, 44. https://doi.org/10.1186/s40779-021-00338-z
Yorumlar
Kullanıcı yorumlarını görüntüleyebilmek için kayıt olmalısınız!